Training Snippets versus System Instruction
There are two basic ways to provide “context information” for your AI chatbot that doesn’t require programming; System Instruction and Training Snippets (RAG). Since the relationship between these two can sometimes be confusing, I will try to explain the difference in this article. However, let’s first ask ourselves exactly what context information is.
What is Context Information?
Context information is information that is automatically transmitted to OpenAI as the user is asking your chatbot a question. Without context information, the chatbot will perform just like a vanilla ChatGPT request, without having any knowledge about your company or organisation. If you add context information, the AI chatbot will be able to use this context as the basis for answering users’ questions. It’s similar to uploading a PDF to ChatGPT and asking it questions about the PDF, except everything happens automatically behind the scenes, and is invisible to the end user.
By providing context information, you can control the LLM’s behaviour, in addition to teaching it new things it didn’t know from before. In addition you can provide “instructions” to the chatbot, such as giving it a name, telling it to answer in a specific language, or for that matter instruct it to answer in the style of Snoop Dogg.
In a way it could be argued that providing context information to the LLM is what makes your AI chatbot unique, capable of answering questions related to your data.
System Instruction
The system instruction is always transmitted to the LLM as an invisible message number 1. If you’re acquinted with OpenAI’s APIs, it’s the “system” message of an HTTP invocation towards their chat API.
Since the system instruction is always transmitted to OpenAI, this makes it a very good place for instructions that are general and should always be sent to the LLM. This makes it highly useful for providing “instructions” such as a tone of voice, in addition to basic information that the AI chatbot should always know. You can edit the system instruction by clicking “Configure” on your type from the machine learning component. Below is an example for an imaginary AI chatbot created for SalesForce, intended to act as a sales executive.
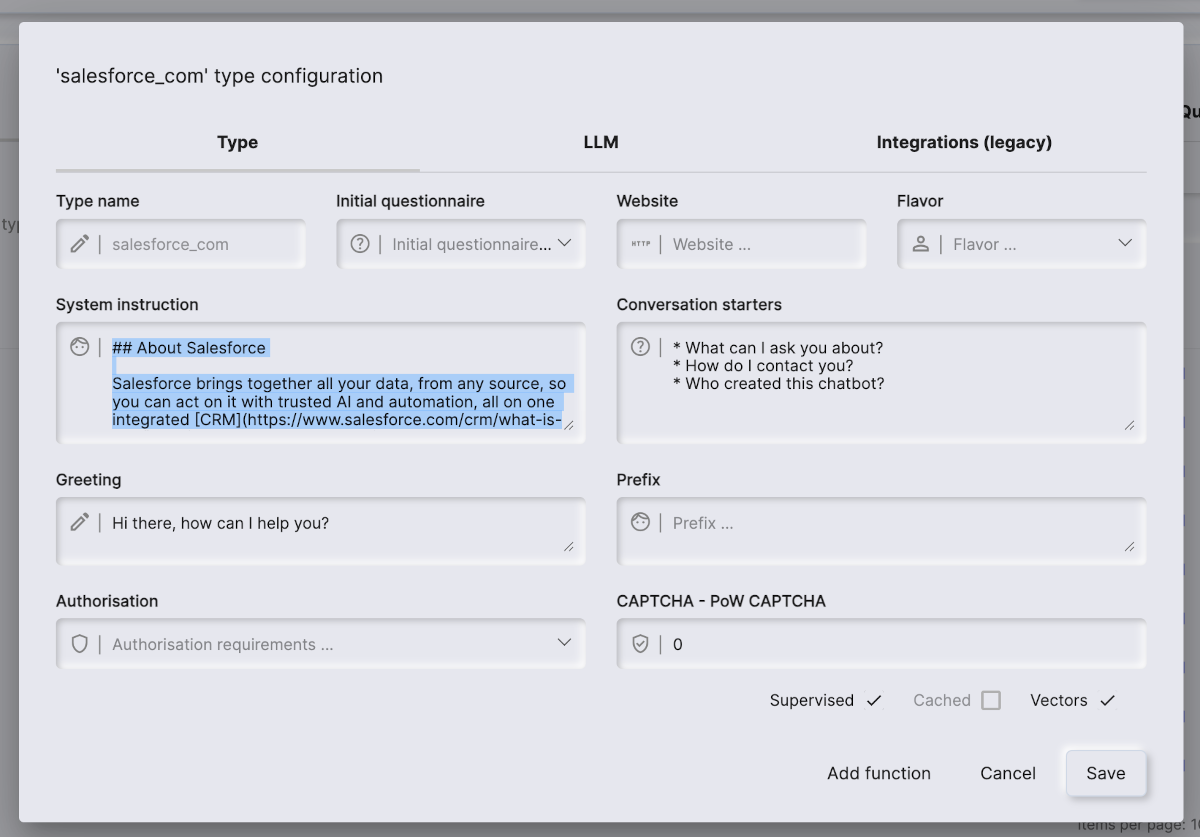
The system instruction should not be too long, but only contain the most important information and instructions required to modify its behaviour according to your requirements. However, there’s no real difference between the system instruction and a training snippet conceptually, since they both end up as context information.
This allows you to provide the most important parts of your expected behaviour to the system instruction, and can for instance contain information such as the name of your company, company phone number, or how to act if the user is showing frustration, etc. Think of the system instruction as the foundation for your AI chatbot, as in the contextual information it should always have access to, regardless of what questions the user is asking.
Training Snippets
Training snippets again are matched according to what questions the user is asking, and you can have thousands of individual training snippets, covering all sorts of different information. When the user is asking a question, the AI chatbot will first generate embeddings for your questions, and then lookup training snippets such that it attaches the most “similar” training snippets as additional context data, before it transmits the request to the LLM.
When a question is being asked, your cloudlet will find the top n matching training snippets, until it’s filled up its context window, and transmit these to the LLM. This allows us to transmit only context information from your training snippets that is relevant to answer the user’s question. If you want to synthesise this behaviour to see which training snippets are a part of a specific question, you can copy and paste your question into the search bar of the “Training data” tab, and check the “VSS” checkbox. Below is a screenshot to serve as an example.
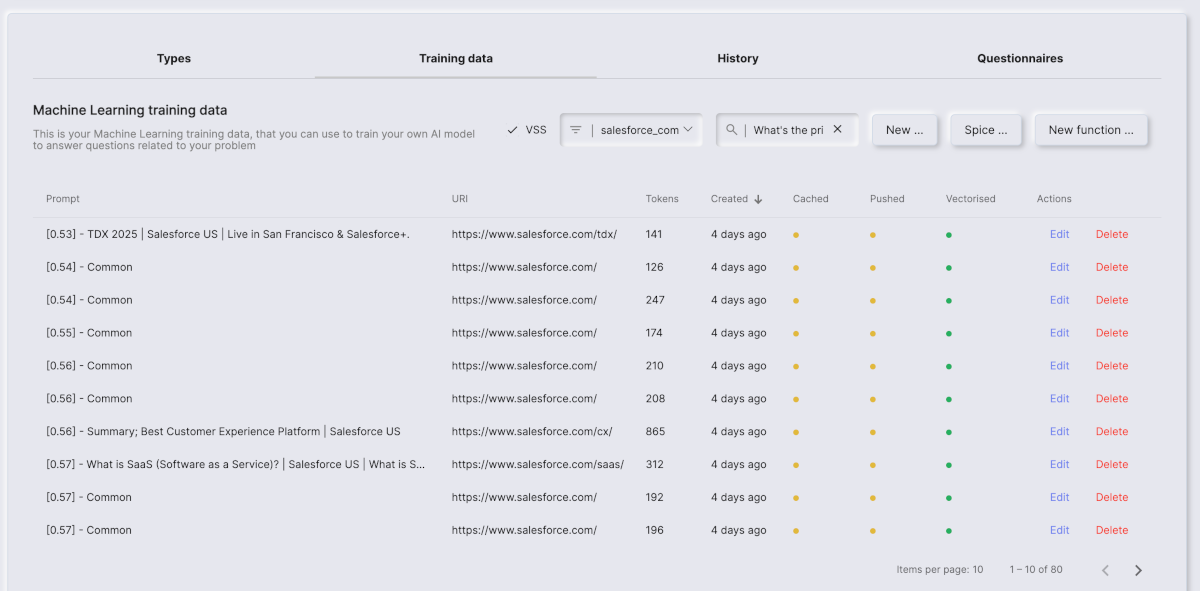
Threshold
In the above image you can see a number in square brackets for each training snippet in the first column. This is the “similarity value” of each individual snippet, and basically the lower this number is, the more relevant the particular snippet is to the question being asked. A similarity of 0 means the question is the exact same content as the snippet. While a similarity of 1 means it’s the exact opposite and completely irrelevant. This allows us to match for instance a question being “What’s the price” towards training snippets containing price information.
Notice, this “similarity” value is also related to the threshold of your configuration - Since only snippets that are within the threshold you’ve got in your LLM tab’s value are considered. Notice, this number is inversed, so a snippet of 0.56 similarity, will be considered if you’ve got a threshold of 0.3, since 0.3 + 0.56 is less than 1.0. A snippet with a similarity of 0.71 again will not be considered, since 0.71 + 0.3 becomes 1.01. This allows you to exclude irrelevant training snippets if they’re below some threshold value in similarity.
Max Context tokens
The “Tokens” column again is important to understand, since it’s the number of OpenAI tokens one specific training snippet is consuming. If you look at your AI chatbot’s configuration, and choose the “LLM” tab, you will see one important field that’s related to training snippets. This is its “Max Context tokens” value. In the screenshot below you can see this number being 4,000 in the bottom left parts of your configuration.
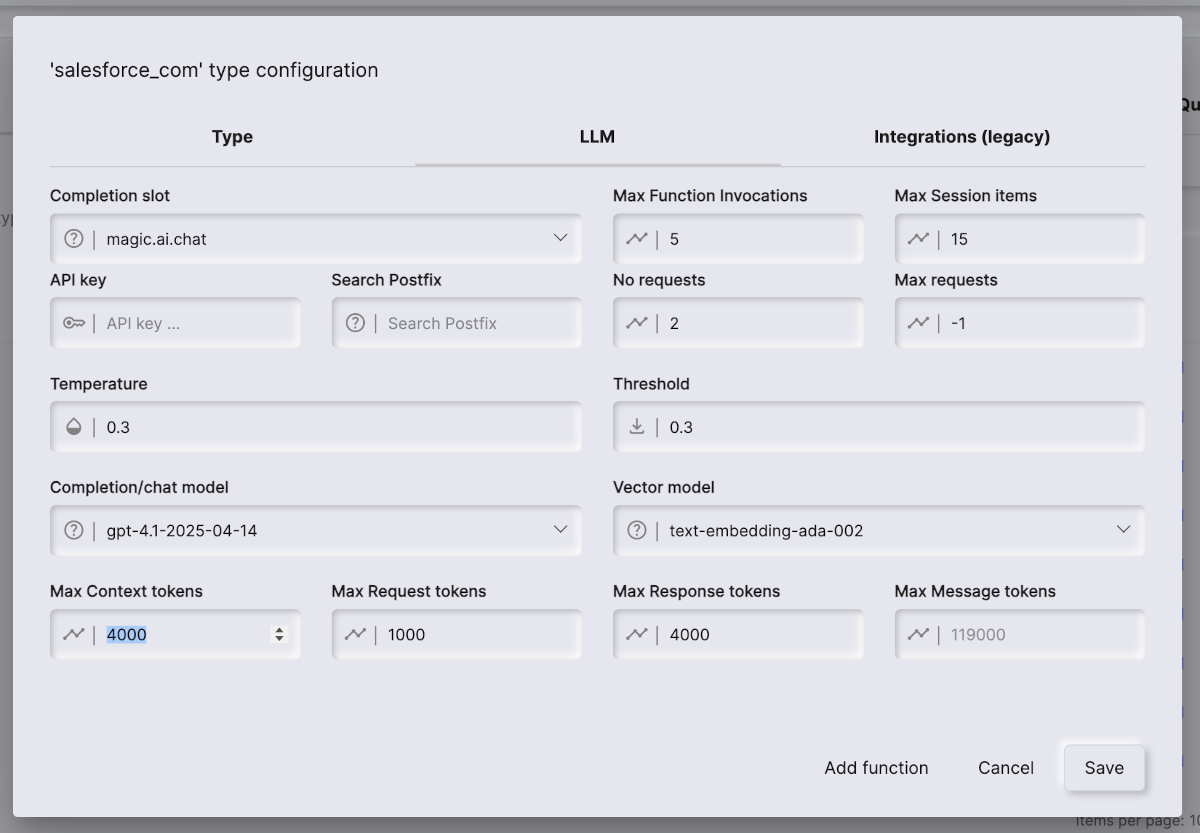
This value is an instruction to the cloudlet of how many tokens to attach from your RAG training snippets, for each individual request. In the above image it’s set to 4,000, while our training snippets from the image above is in the range of 126 to 865.
When a question is being asked, the cloudlet will retrieve the most relevant training snippets, and start adding context information from the top of the list returned, until it has filled up its context window with a maximum of 4,000 tokens, or it can no longer find snippets with a similarity that’s within the “Threshold” value of your type.
Notice, this implies that if you’ve got an individual training snippet that’s 4,001 tokens, this snippet will never be used. As a general rule of thumb, we advice to never create snippets that are larger than 80% of your “Max Context tokens” value. During import or website scraping however, we automatically reduce the size of snippets such that they never exceed this 80% threshold.
For our “What’s the price” example above, it will probably have room for all training snippets on page 1, and possibly add some 15 to 20 training snippets to the request in total. The cloudlet will never add more than 4,000 tokens in total though from your training snippets, and it will never add snippets that’s not within the “Threshold” value for your type.
This allows you to modify the “Max Context tokens” value of your type to reduce or increase how much context you want to provide. In general more context is better, but also more expensive, since it will consume additional input tokens when invoking OpenAI. In general, 4,000 is the “sweet spot” for context tokens, and 0.3 for threshold - Unless you have special requirements.
Rolling context
“Rolling context” is a concept we’ve invented ourselves, and significantly increases the quality of the chatbot’s response. To understand the concept you first have to realise that AINIRO’s AI chatbots are “conversational AI chatbots”. This implies it will remember previous questions, and previous contexts, until it’s filled up the available context window the specific model you’re using is capable of dealing with (as a general rule of thumb).
This is what allows users to for instance ask questions like “Who’s your CEO”, for then to get an answer and continue with follow up questions such as “Can you show me an image of him”. The word “him” being the subject of the conversation here, and since the LLM will be given previous questions and answers from the same conversation, the LLM will automatically associate “him” with the CEO from the previous answer, and display in image of the CEO if it’s got that in its context.
Since every question triggers a new context due to VSS search through your training snippets for each question asked, this allows us to attach multiple contexts for each question, by preserving the previously used contexts for consecutive questions. Only when the total available context window for the LLM is exhausted, the cloudlet will start “pruning” messages from the top of the conversation to avoid overflowing the LLM with too many input tokens. This implies that for gpt-4o for instance, we’ve got 128,000 tokens to use at most. With a 4,000 max context value for individual requests, this implies that for each question an additional 4,000 tokens are associated with the request as context, until we reach the max value of the LLM.
Notice, the “Max response tokens” value is deducted from the LLM’s context window to give room for the answer from the LLM. So for this example, it will have a maximum value of 124,000 for context information, since 128,000 (size of LLM) - 4,000 (response tokens) becomes 124,000.
Also notice, that gpt-4.1 has a context window of 1 million tokens, and we will cap this at 128,000 by default, since providing 1 million context tokens for a support AI chatbot is beyond overkill for 99% of our users, and might become very expensive over time.
However, due to our “rolling context” concept, the AI chatbot will basically “become smarter for every question asked” until it’s filled up its available context window.
System Instruction or Training Snippets?
So, what should you choose as your primary source for adding information to your AI chatbot? Actually, there’s no real difference between the system instruction and training snippets, and they can both take both instructions and information.
Our general rule of thumb is that the most important information, such as contact us information, name of company, etc, we add to the type’s system instruction. While more dynamic data, such as information about specific products or services, we add as training snippets. This is because the system instruction is always there, implying whatever you write into its system instruction will always be available for the LLM to use as information to answer questions - While training snippets needs to match the question asked.
We suggest you keep your system instruction small in size though, max 2 pages of text in a PDF document roughly, unless you’ve got special requirements. While you add additional information as individual training snippets.
And there’s nothing preventing you from adding “instructions” to individual training snippets, such as for instance “If the user wants to contact a human being, then ask the user for his or her email address, before …blah, blah, blah …“
Wrapping up
In this article we discussed the relationship between the system message of your machine learning type and its training snippets. We showed how we’re using VSS and embeddings to match questions towards your training data, to transmit context information to the LLM - In addition to the relationship between the “Max context window” size, “Threshold” value, and how this is used to extract relevant information from your training snippets as you’re prompting the LLM.
If you find this difficult to understand, AINIRO is providing this as a service to our clients, and we’d love to help you out creating an amazing AI chatbot for your company. If you’re interested in having us help you out, you can contact us here.